





A few weeks ago we introduced you to the concept of text-mining in Biotech through this article. Now that you’re more familiar with the concept, let’s ‘mine’ a bit into the current challenges in this field and how to overcome them.

Data produced through Biotech research grows with an incredible rate. Everyday, scientists are finding new links between molecules, diseases or life mechanisms. This ‘Big Data’ phenomenon can become overwhelming for researchers who are searching for a precise answer. That’s where text-mining can be helpful. Specific algorithms behind this technology are capable of sifting through huge amounts of data to find the specific answer to an unanswered question.
To show you how powerful it could be, just look at the example below where we asked a text-mining tool to show us which genes are associated with breast cancer:
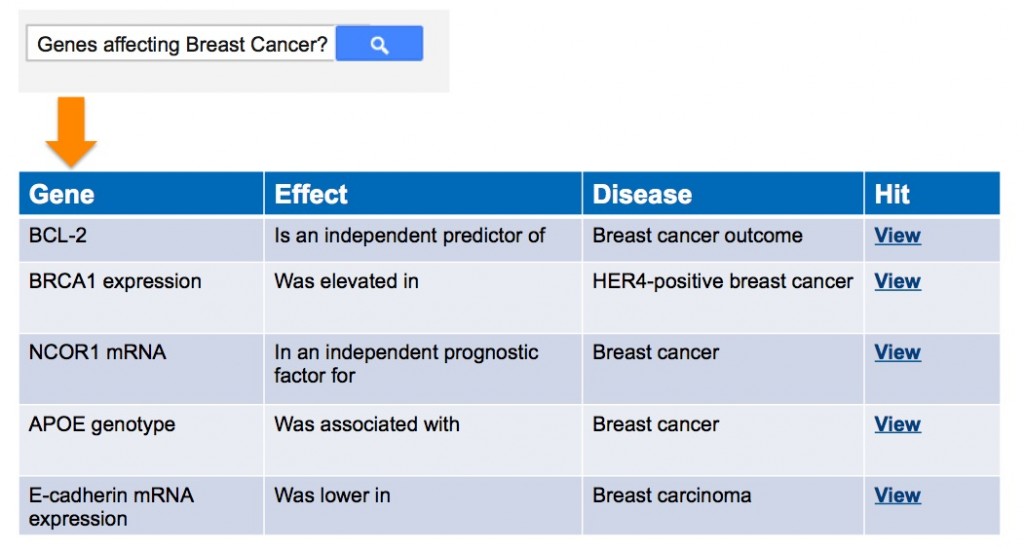
Try to run the same inquiry in a standard database such as PubMed and you will get a long list of results, which you will have to read and analyze to find any relevant answer… So no doubt, text mining is the future for Big Data analysis.
The advantages of these tools is that R&D teams can accelerate delivery of results, as well as reveal hidden relationships within literature to develop new hypotheses. For further details, you can have a look at our previous article.
But current text-mining tools also have some limitations:
- Mining is often limited to abstracts; researchers can’t mine full text content to which they are not subscribed.
- There could be technical challenges to import your own article database within the text mining tool
- Converting documents (mostly in PDF) into the XML format* is both time consuming and complex
*XML format is a markup language that defines a set of rules for encoding a document in a format which is both readable by human and machine.

As shown on the figure above, text-mining gives good results but the amount of manual preparation work is significant. And until now, no single solution addresses these issues.
The solution: XML for Mining
XML for Mining fills the gap between the documents search and the results of the text mining tools. It will reduce the manual work within the basic workflow (above)

XML for Mining is a database of +950 millions papers created by RightsDirect, a copyright licensing specialist. This database expands the capability of a company’s text mining efforts beyond subscribed full text articles, abstracts and Open Access articles, allowing searching and downloading of the full-text of all articles, subscribed or not.
As all CCC’s content is pre-authorized for commercial text mining, you can be confident that your project complies with copyright.
XML for Mining reduces time and cost! It allows for full text article access and normalizes the various XML content from multiple publishers into a secure cloud for fast and easy access, reducing the time and costs associated with article conversions, content management, and negotiations with publishers regarding text mining rights.
XML for Mining is adaptable to all text-mining tools so you don’t need to invest in a new software solution.
With its strong database, XML for Mining has the potential to facilitate text mining in the Biotech space and is able to enhance innovation.